Robots.txt là một file quan trọng trong quá trình xây dựng website nhằm khai báo cho các công cụ tìm kiếm thu thập các thông tin dữ liệu trong thời gian sắp tới. Hãy cùng Kiến Thức SEO tìm hiểu thêm về file Robots.txt này nhé.

Giới thiệu về Robots.txt
Robots.txt là một tệp văn bản đơn giản có đuôi mở rộng .txt, nằm trong thư mục gốc của một trang web. Tệp này chứa các chỉ thị cho các trình thu thập thông tin của các công cụ tìm kiếm như Googlebot, Bingbot, và nhiều loại trình thu thập khác. Nhờ vào Robots.txt, quản trị viên website có thể kiểm soát việc thu thập dữ liệu của các công cụ tìm kiếm, từ đó hướng dẫn chúng về những phần nào của trang web được phép truy cập và thu thập dữ liệu.
File Robots.txt có chức năng gì?
File Robots.txt không chỉ đơn thuần là một tệp tin mà còn giữ vai trò quan trọng trong việc tối ưu hóa SEO cho website. Cùng tìm hiểu các chức năng:
- Quản lý lưu lượng truy cập: Hạn chế số lượng yêu cầu từ các trình thu thập thông tin đến server, làm giảm tải cho máy chủ.
- Bảo vệ nội dung riêng tư: Ngăn chặn các trình thu thập truy cập vào những phần của website mà quản trị viên không muốn công khai.
- Tối ưu hóa quá trình lập chỉ mục: Hướng dẫn các công cụ tìm kiếm tập trung vào những nội dung quan trọng, giúp cải thiện thứ hạng tìm kiếm.
Cấu trúc của File Robots.txt
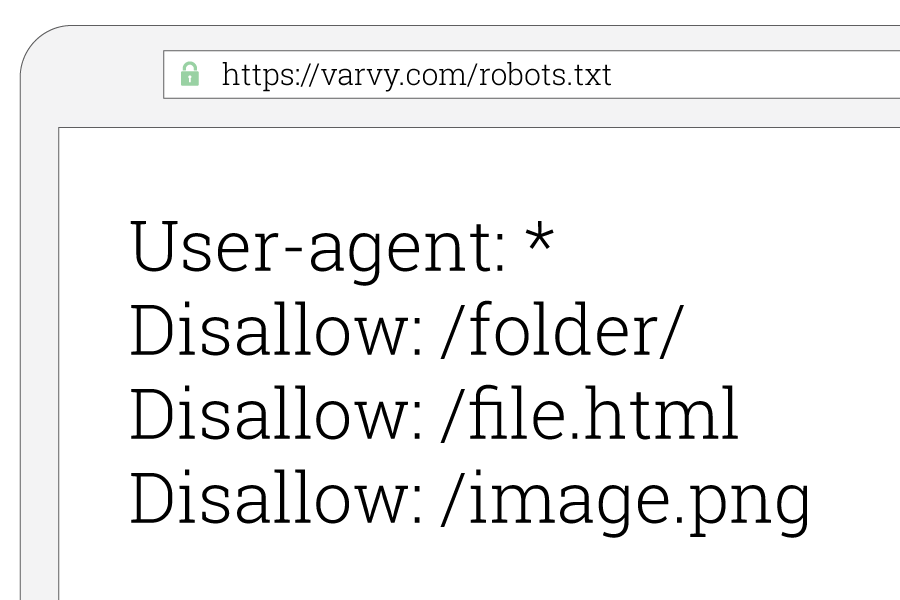
File Robots.txt có cấu trúc rất đơn giản, bao gồm các dòng chỉ thị, mỗi dòng bắt đầu bằng một từ khóa cụ thể. Đây là các từ khóa phổ biến mà bạn sẽ gặp trong tệp Robots.txt:
- User-Agent: Chỉ định loại trình thu thập thông tin mà chỉ thị này áp dụng. Đó có thể là một trình thu thập cụ thể hoặc dấu hoa thị (*) để chỉ định tất cả các trình thu thập.
- Disallow: Chỉ định các URL mà trình thu thập không được phép truy cập.
- Allow: Chỉ định các URL mà trình thu thập được phép truy cập, thường sử dụng để ghi đè lên quy tắc Disallow.
- Sitemap: Chỉ định URL của sitemap của trang web, giúp trình thu thập biết nơi tìm kiếm thông tin.
Dưới đây là một ví dụ minh họa về cấu trúc của tệp Robots.txt:
User-agent: *
Disallow: /private/
Allow: /private/public-page.html
Sitemap: https://www.example.com/sitemap.xml
Các lệnh trong Robots.txt mà Google hỗ trợ
Trước khi tạo file robots.txt, cần hiểu rõ các lệnh mà Google hỗ trợ. Điều này rất quan trọng vì Google là công cụ tìm kiếm chính mà hầu hết các quản trị viên web sử dụng. Dưới đây là mô tả một số lệnh cơ bản:
User-Agent là gì?
User-Agent là tên của ứng dụng tự động (trình thu thập dữ liệu của công cụ tìm kiếm). Đây là câu đầu tiên trong mỗi nhóm quy tắc. Danh sách các tác nhân người dùng của Google bao gồm:
- Googlebot
- Googlebot-Image
- Googlebot-News
- AdsBot-Google
Dấu hoa thị (*) đại diện cho tất cả các trình thu thập dữ liệu, ngoại trừ AdsBot, cần chỉ định tên cụ thể cho loại này.
Disallow là gì?
Disallow chỉ định các thư mục hoặc trang mà bạn không muốn trình thu thập dữ liệu truy cập. Nếu quy tắc đề cập đến một trang, tên trang đó phải được ghi đầy đủ. Quy tắc này bắt đầu bằng ký tự / và nếu quy tắc đề cập đến một thư mục, thư mục đó cần kết thúc bằng dấu /.
Ví dụ:
User-agent: *
Disallow: /private/
Disallow: /temp/
Allow là gì?
Allow cho phép trình thu thập dữ liệu truy cập vào một thư mục hoặc trang cụ thể mà thường bị cấm bởi quy tắc Disallow. Điều này rất hữu ích khi bạn muốn cho phép thu thập dữ liệu một trang con trong một thư mục không được phép.
Ví dụ:
User-agent: *
Disallow: /private/
Allow: /private/public-page.html
Sitemap là gì?
Sitemap không bắt buộc phải có trong tệp robots.txt nhưng rất hữu ích. Nó chỉ định vị trí của sơ đồ trang web cho trang web, giúp các công cụ tìm kiếm biết nơi tìm kiếm thông tin. URL sơ đồ trang web cần là một URL hợp lệ.
Ví dụ:
Sitemap: https://www.example.com/sitemap.xmlHướng dẫn tạo file Robots.txt cho website
Việc tạo File Robots.txt cho website không quá phức tạp. Dưới đây là hướng dẫn cụ thể cho các loại website phổ biến.
Tạo Robots.txt cho website WordPress
Đối với website WordPress, có thể dễ dàng tạo và chỉnh sửa File Robots.txt bằng cách sử dụng các plugin SEO như Yoast SEO hoặc All in One SEO Pack. Các bước thực hiện như sau:
- Cài đặt và kích hoạt plugin SEO.
- Truy cập vào phần cài đặt của plugin.
- Tìm kiếm phần Robots.txt và bắt đầu chỉnh sửa theo nhu cầu.
Ví dụ, nếu muốn ngăn không cho Google truy cập vào thư mục wp-admin, cấu trúc sẽ như sau:
User-agent: *
Disallow: /wp-admin/
Tạo Robots.txt cho website 2.0
Đối với các nền tảng website 2.0 như Wix, Blogger hay Squarespace, việc tạo File Robots.txt có thể hơi khác. Nhiều nền tảng này tự động tạo File Robots.txt cho người dùng. Tuy nhiên, nếu cần tùy chỉnh, hãy tìm kiếm trong phần cài đặt hoặc hỗ trợ của nền tảng đó để xem có tùy chọn chỉnh sửa hay không.
Tạo Robots.txt cho Next.js
Khi làm việc với Next.js, bạn có thể tạo file robots.txt trong thư mục src/app/robots.ts. Tạo một tệp có tên Robots.ts hoặc Robots.js và thêm các quy tắc mà bạn muốn sau đó khi Build dự án Nextjs sẽ tự động tạo ra 1 file Robots.txt. Ví dụ:
User-agent: *
Disallow: /api/
Allow: /
Sitemap: https://kienthucseo.net/sitemap_1.xmlSau khi tạo xong, File Robots.txt sẽ tự động được phục vụ từ đường dẫn https://yourdomain.com/robots.txt.
Cách kiểm tra Robots.txt hợp lệ
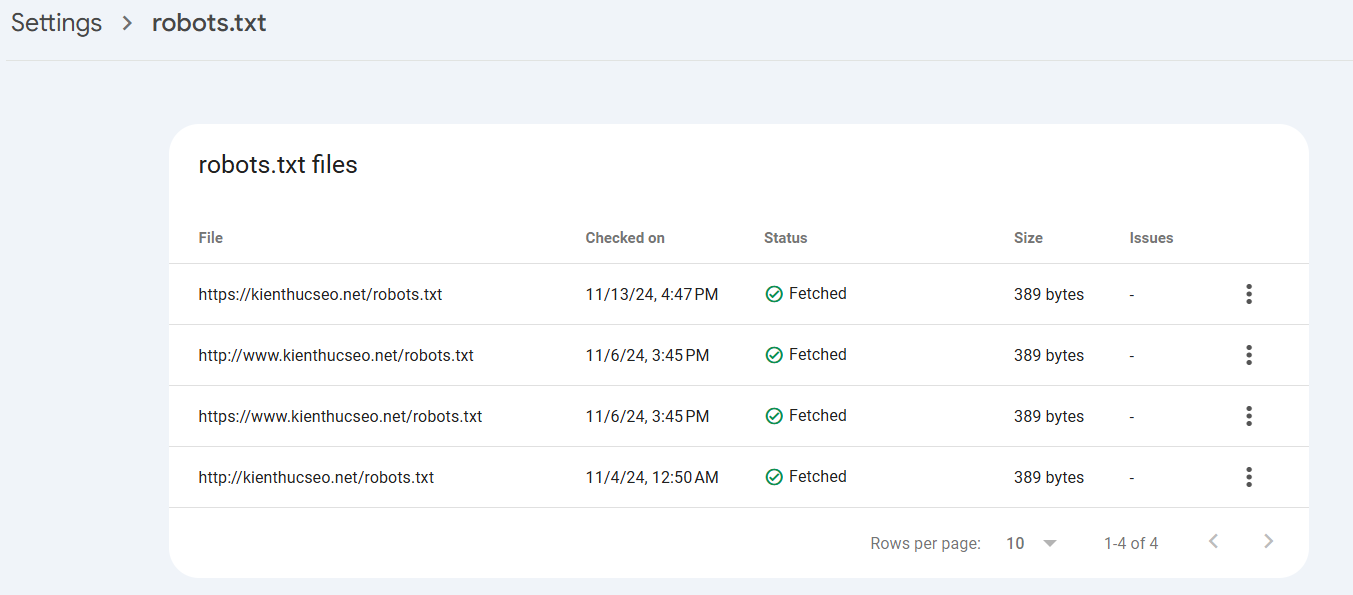
Sau khi tạo File Robots.txt, điều quan trọng là phải kiểm tra tính hợp lệ của nó. Cách tốt nhất để làm điều này là sử dụng Robots.txt Tester trong Google Search Console. Các bước thực hiện như sau:
- Đăng nhập vào Tài khoản Google Search Console.
- Nhấp vào mục Robots.txt Tester trong phần Crawl.
- Trong đó sẽ hiển thị những file mà bạn đã cấu hình, nếu muốn cào lại bấm chọn Request a Recrawl.
Nếu mọi thứ đều ổn, sẽ chuyển sang màu xanh và hiển thị nhãn Fetched. Ngược lại, nếu có lỗi, bạn hãy kiểm tra lại cấu hình trong File xem đã hợp lệ chưa và tiến hành Crawl lại.
Lưu ý khi sử dụng Robots.txt
Mặc dù Robots.txt là công cụ hữu ích, nhưng cần lưu ý rằng:
- Robots.txt không phải là phương pháp bảo mật: Tệp này không phải là cách để ẩn trang web khỏi các công cụ tìm kiếm. Các trình thu thập thông tin có thể bỏ qua các chỉ thị nếu chúng cho rằng các chỉ thị này không hợp lệ hoặc có hại.
- Chỉ là hướng dẫn cho các trình thu thập thông tin: Các trình thu thập thông tin có thể bỏ qua các chỉ thị trong File Robots.txt nếu chúng cho rằng các chỉ thị này không hợp lý hoặc không có lợi cho người dùng.
Kết luận
Tệp Robots.txt đóng một vai trò quan trọng trong việc quản lý và là yếu tố quan trọng của Technical SEO cho website. Việc kiểm tra và cập nhật thường xuyên File Robots.txt sẽ giúp tối ưu hóa hiệu quả thu thập dữ liệu và nâng cao thứ hạng tìm kiếm của website.
Hy vọng qua bài viết này, Kiến Thức SEO đã giúp bạn hiểu rõ hơn về Robots.txt và cách cấu hình nó cho website của mình. Nếu có bất kỳ câu hỏi nào, đừng ngần ngại chia sẻ để cùng thảo luận nhé!








